

by Evan Bretl.
One of the most critical functions of any autonomous vehicle is the ability to perceive its environment. Much of a typical robotics technology stack (mapping, planning, motion control) would be impossible without adequately sensing and comprehending the surroundings. Given the fundamental nature of machine perception to a functioning autonomous robot, RoboJackets software subteams have developed a number of interesting, practical perception solutions. This article will focus on RoboNav’s and RoboRacing’s perception techniques specifically, with coverage of other teams potentially coming in the future.
The first focus of this article is RoboNav’s neural networks, which were developed for use in the IGVC competition. The purpose of these neural networks is to take an input image from the forward-facing camera and determine which pixels in the input image represent painted lines.

The pixels for these detected lines can then be virtually “projected” on the 3D world around the robot so that the location and shape of out-of-bounds lines are known to the rest of the autonomy system.
The technique RoboNav uses to achieve this is a type of machine learning model called a U-Net. Many other machine learning techniques for image data might output a prediction for whether certain classes of objects (e.g. cat, car) are anywhere in the image; in contrast, a U-Net outputs a prediction for every pixel. The predicted values are probabilities that each pixel is a line, based on the examples of lines that it was shown during training.
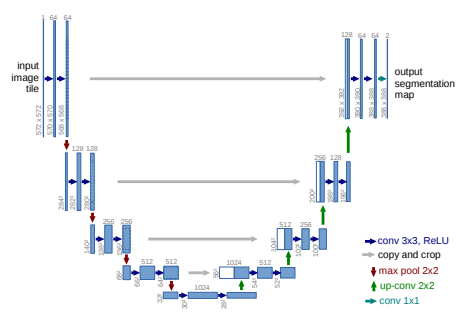
RoboNav has used this “binary” line detection model at IGVC competitions in the past, but a machine learning model that could identify pixels that contain other objects like barrels and other obstacles on the course would provide extra utility. Well, the team has solved that too with a multi-class U-Net. Each pixel in a multi-class prediction image contains the relative probabilities that a pixel is a white painted line, a barrel, or neither. Multi-class U-Nets require significantly more training data than binary U-Nets, so for the RoboNav to get good performance with such a model is an achievement.

Where can RoboNav go from here? The team is planning to integrate LIDAR point clouds into the detection of barrels and other objects using a class of algorithms called 3D semantic segmentation. In 3D segmentation, a different kind of machine learning model predicts whether LIDAR points (rather than image pixels) belong to a particular category.

The second focus of this article is RoboRacing’s computer vision algorithms for the International Autonomous Robot Racing Competition (IARRC). The team calls these algorithms “detectors” of certain key features in the competition environment. These features include colored tape lines on the ground, stoplights, traffic cones, and signs with direction arrows. Detectors for multiple features may run concurrently to look for multiple features at once; for example, the robot may want to reason about white tape lines marking the edge of the track, orange cones to avoid inside the course, and the magenta start/finish line. Unlike RoboNav’s U-Net, these detectors are hand-engineered rather than machine-learned.
One of RoboRacing’s key computer vision algorithms detects white painted lines. This detector processes the camera image in multiple stages. First, the Laplacian edge detection algorithm produces a binary image that is white at sharp changes in color (such as the edge of the lane line). This binary image has many false positive line detections but few false negatives. Second, the camera image is run through adaptive brightness thresholding, producing a binary image that is white where a pixel is significantly “whiter” (high brightness, low saturation) than its surrounding area. This method gives very few false positive line detections, but it does have false negatives. These binary images are combined by extending the adaptive brightness result with the edge detection result (or, in other words, using the adaptive brightness result to filter out false positives from the edge detection result). The combined result gives a binary detection image for white lines that is robust to changes in lighting conditions without significant tuning.

Another key computer vision algorithm for RoboRacing detects orange traffic cones. This one can be simpler than the line detection because the color of these cones is so much different than the surroundings; it’s not a bad assumption that if a pixel is some shade of orange, it’s probably part of a cone. What is “orange” is described as a certain range of hue and saturation levels (in the HSV color space). These groups of orange pixels are filtered by size, so that there are not false positives that are just a few pixels in size. Using a pinhole projection camera model and the known height of the cones, the height of each group of orange pixels can give us an estimate of the distance to the cone.
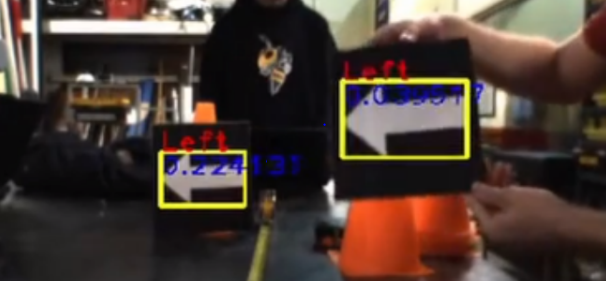
To detect signs with direction arrows for the IARRC urban challenge, RoboRacing has another hand-engineered classifier. This software uses Canny edge detection to find the strong edges of the white-on-black arrow shape. These edges which form closed shapes are processed based on the number of edges (after polygon simplification; the arrow shape should have seven), based on width-to-height ratio, and based on Hu Moments.
These applications of robotics and computer vision research provide new tools to help RoboJackets teams succeed in competition. More importantly, as documented in the RJ Research series, the algorithms and techniques applied in competition inspire our current and future members to develop the next technological advances in robotics.